In this post, I will detail how I tackled the problem of building a context and relevance-aware NER system for financial news entity detection.
The problem
We are tasked to build a model to extract company names from financial news, but only if the companies are directly relevant to the news article.
For instance, consider a random financial news article about weight-loss drug companies like Novo Nordisk: While the article also mentions big tech companies like Nvidia and Apple, they are not relevant to the story, and ideally should not be extracted.

However, applying a pretrained NER model like NER-BERT extracts all entities from text, regardless of whether the entity is relevant to the story or not. This presents us our first problem: Entity recognition models are trained mainly to extract all entities without awareness of document meaning. One possible solution is to finetune a pretrained NER model on financial news, but the task we need (relevance classification of entities) is fundamentally different.
We also encountered a second problem while attempting to solve this problem: Often times, the names of companies relevant are mentioned multiple times in one news, but differently. As typical entity detection models only return classifications for each token in the text, we would get multiple extracted results for what is actually just one entity. For example, consider the following example from CNBC news:
Broadcom (AVGO) CEO expects AI windfall even as sales growth slows:
Broadcom Inc., a chip supplier for Apple Inc. and other big tech companies,
expects the rapid expansion of artificial intelligence computing
to help offset its worst slowdown since 2020...
In this example, the pretrained NER model picked up the stock ticker AVGO, Broadcom and Broadcom Inc. as separate entities. Our solution was to use a finetuned LLM (FLAN-T5) to handle all the entity resolution logic, picking out the required companies, and then feeding our results into a classifier (CrossEncoder) to determine each entity’s relevance.
Using our two-stage approach, we are able to successfully detect and score the relvance of companies for each financial news. As seen from the figure above, we extract Novo Nordisk as the only relevant entity to the news.
Training the relevancy model
In order to build a relevance classifier for entities to news, we use a proprietary dataset with human-labelled relevance scores for financial news, like so:
| News | Entities |
|---|---|
| news1 | [(Apple Inc, 0.9), (Microsoft Corp, 0.65), …] |
| news2 | [(AMD Corp, 0.85), (JP Morgan, 0.35), …] |
We explode the entity column as:
| News | Entity |
|---|---|
| news1 | (Apple Inc, 0.9) |
| news1 | (Microsoft Corp, 0.65) |
| news2 | (AMD Corp, 0.85) |
| news2 | (JP Morgan, 0.35) |
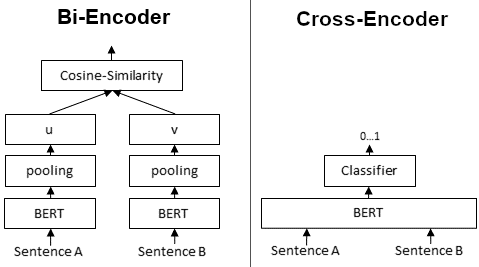
Model 1: Bi-encoder embeddings
Our first idea was to finetune a SentenceBERT embedding model to be able to produce separate embeddings for document and entities, and define our loss function using the cosine similarity between each pair of news and entity embeddings.
Model 2: Cross-encoder classifier
The second model was to use a question-and-answer model pretrained on MS Marco, and finetune it to take in each pair of <news, entity> as query and answer for input. Ultimately, this produced slightly better results, and we went with this.
Results:
| Model | Accuracy | Precision |
|---|---|---|
| bi-encoder (base) | 0.711 | 0.767 |
| bi-encoder (finetuned) | 0.814 | 0.87 |
| cross-encoder (base) | 0.657 | 0.759 |
| cross-encoder (finetuned) | 0.86 | 0.91 |